{kind=link}


聲音合成
很意外這可能是最令人興奮的部分,尤其對於音樂工作者來說。
能夠創造出自己獨有的聲響應該是夢寐以求的事,早在2017年由 Google AI 底下的 Magenta 便有一個名為 NSynth 的計畫,試著使用深度神經網絡的方式來合成聲音,網頁上可以聽到一些例如貝斯加長笛的聲音,如果你是 Ableton 的使用者,也有 Max Device 可試用。其實這樣的聲音並不至於無法想像,甚至很容易悅耳,挑戰可能在於創造出音色後彈奏出屬於它的表情。
 ▲ NSynth 在 Ableton 中運作的狀況。
▲ NSynth 在 Ableton 中運作的狀況。
行至今日,Qosmo Neutone 在這類型的聲音合成器中,是最值得被關注的一個。VST3/AU 的格式可在大部分的 DAW 中運行,它們所建立的社群也有許多人在其中分享自己的建模(SDK)。
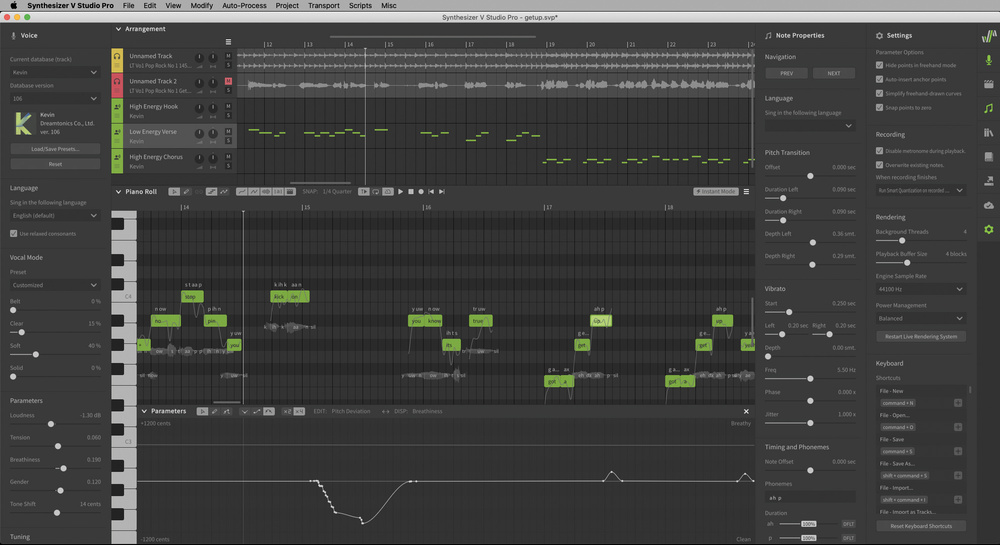
人聲合成
之前曾花過一整個篇幅來介紹如何「複製」人聲,而如果想要更自由的創作,Dreamtonics Synthesizer V 應該是不錯的選擇。使用上如同一般的 DAW 介面,只要輸入音符跟文字,就可以用已建立好的模型幫你「唱」出來,目前只支援英、日、中三國語言,不過卻能找到有才的網友利用羅馬拼音唱出惟妙惟肖的台語。
想像你自此得到數個隨時可錄 demo 的歌手,而且不再有音準問題。
取樣與建模
我們身處於一個對於各式音樂、人聲取樣仍有非常複雜版權及法律規範的時代,未來 AI 創作出的內容是否需在規範內也多有討論,但少數能肯定的是「聲音處理」成了無涉版權,又商機無限的地方。Neural DSP Quad Cortex 這類的產品可以讓你先送出訊號(capture out)到任一機器,也許是六零年代的 Fender 音箱,又或是一顆稀有的 pedal,再回送到 Quad Cortex 本身後即完成取樣,這讓音樂家們對於音色的創造跟掌控又更進了一步。
而如果這樣的技術已經能夠「下放」到一般人可負擔的機器時,廠家從之前傳統的 DSP 模擬需要「猜測」各種模擬組件的效果及其相互依賴性,直到如今使用 AI 的更便宜、更快,意味著這些低成本、高質量模擬模型的激增,許多珍禽異獸經典銘機將不再遙不可及。

可以自動化的部分
之前曾多次提及 iZotope 或 sonible 這些發展 AI 混音及母帶後期處理工具的公司,多年來產品有著聽感上顯著的進步。此類聲音處理建模的想法部分是基於例如:重金屬音樂中的電吉他總是在某個頻率段有著巨大能量,又或是爵士音樂中大鼓所占據頻率段的位置。隨著運算能力增強以及模型數量增大,一如修圖軟體,終將能夠做得比一般人更快更好。
很遺憾地說,除了創作者本身,聽眾並不在乎創作的細節甚至過程,今日線上的母帶後期處理服務,大部分結果無法分辨是由 AI 或是人所為。
MIDI 還有搞頭嗎?
比起試圖在 MIDI 技術上革新(MIDI 2.0)而又無人聞問,透過 MIDI 來拆解學習並創作音樂的 AI 工具似乎比較能讓這個已經四十年的科技有個較為光明的未來。無論是能在 DAW 中使用的 Mixed In Key Captain,還是網頁形式的 AIVA,都能以此創造出樂句,並輸出 MIDI 檔案以供修改。
與目前被廣泛應用在 AI 創作上的圖像以及文本不同,音樂是一個有「時間軸」的藝術形式,即使目前工具已經能產出某種樂風的起承轉合,這反而是最為需要人為介入的一個環節,畢竟與音訊相比,MIDI 所能承載的資訊量還是過低,容易聽起來笨拙。
如果你研究過因 ChatGPT 而大熱的公司 OpenAI,會發現它也曾有過以此為概念的專案 MuseNet,但似乎無意商品化。

撰文:Jungle
重返青春熱血的社團時光,5月23日樂手巢雜誌 Vol.17 正式出刊:
https://ysolife.com/yso-mag-vol-17/